
Error Regression Scheme - Part 2
Part 2. How We Do It
In the previous posting, I briefly introduced the Error Regression Scheme (ERS). In this posting, I’ll talk a bit more about how we actually use the ERS in our experiments.
Before We Start - Keywords
Before we start to talk about the ERS, there are a few keywords to begin with.
Internal State, Activation Value and Initial State
Internal states (u) are the neuron’s value before the activation function (f) is applied. Then, y is the activation value of the neuron. That is,
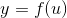
where f is the activation function, such as sigmoid, hyperbolic tangent, etc. Initial state is “the initial internal states“ of the neuron. “Initial” indicates the onset of the computation (usually t = 0). So, initial states refer to the internal states of the neurons at t = 0.
Basic Ideas
As I mentioned in the previous posting, the simplest way to understand the ERS is to consider it as a sort of online optimization techniques. During the conventional training process, we optimize weights and biases. During the ERS, we optimize the initial states only, with given (optimized) weights and biases. To perform the ERS, we first have to consider the followings:
When do we perform the ERS?
The ERS is performed in an online manner. That is, it is performed at each time step (t) during the testing phase.
Which error should be minimized?
At each time step t, we minimized the error at the output layer. To be more specific, the error is a sum of the errors obtained in the recent past (from t-w to t), and the error is often defined as the distance between the model’s output and the target (i.e. teaching signal). That is,
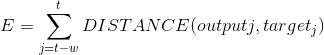
This shows one of the differences between the conventional training method and the ERS. During the conventional training method, we consider the error from the beginning to the end of the sequence (t = 0 to T, where T is the size of the sequence). During the ERS, the error in the immediate past (t-W to t) is considered. This time span is called the Error Regression Window and its size is noted as W.
*Error Regression Window
The time (from t-W to t) indicates the immediate past and we are only interested in the error during this period of time (i.e. within the Error Regression Window). The size of the error regression window can be considered as how long we observe the past information. Then, we can have another questions - how do we set the size of the window? Well, it depends on the characteristics of the data that the model handles. If the size of the window is small, sometimes the model can be trapped in the local minimum. If the size of the window is extremely small (say k = 1), then the ERS is performed in a way that the model tries to make accurate prediction for only 1 time step. There could be many solutions (i.e. local minimum) which generate correct prediction for that time step. If the size of the window is too big, it might be hard to find the solutions and also it might slow down the computation. The rule of thumb (from my experience) is that the size of the window might need to be big enough to contain 0.5 ~ 1 cycle of the data.
How do we minimize the error?
During the ERS, the initial states of the Error Regression Window ($u_{t-W}$) is iteratively updated to minimize the error. That is,
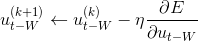
$\eta$ is a learning rate, E is an error and k indicates the index of the iteration. The above computation is performed iteratively at each time step. The maximum number of k is another hyper-parameter in the ERS that has to be specified by the experimenter. I often set K = 50 or 100 depending on the task.
*What does it mean by updating the initial states of the window?
During the ERS, we only update the initial states of the window - which is “past information” which predicts the observation in the immediate past. So this can be roughly interpreted as follows. When there is an prediction error at the current time, we update (modify) our belief in a short time ago. In computation, the current time step (t) and the immediate past (t-W) can be explicitly distinguished. But how do we perceive time? Is there any distinct separation between past and now? What’s nowness? In Jun’s book, this concept is explained in terms of retention, primary impression and protention. If you’re interested in this concept behind the ERS, please check Jun’s book Chapter 3.3. Time Perception: How Can the Flow of Subjective Experiences Be Objectified?.
So, How Do We Do the ERS? - Pseudo Code
This example illustrates how we perform the ERS. It’s pretty simple and straightforward.
|
|
At each time t, we iteratively update InitialStates in the direction of minimizing error. Once the iteration ends, we move on to the next time step (t+1). Note that generation of prediction is done in the closed-loop manner. It means the model’s output at t is fed back to the model’s input at t+1. See here for more explanation about the closed-loop generation.
Tips & Tricks
- At the beginning of the ERS, there are cases where current time step is smaller than the size of window (W). For instance, there can be a case where W is 40 and the current time step is 3. To handle this kinds of situations, you can either start the ERS from the time step W (e.g., performing the ERS from t = 40), or you can perform the ERS with the less info at the beginning of the ERS (e.g, use 1 to t, instead of t-40 to t).
- Usually, the learning rate during the ERS is bigger than the one during the training process.
- The size of the Error Regression Window depends on the task. Just try with the different length and see what happens. I prefer to set it big enough to contain 1 cycle of the data.
- The number of iteration at each time step also depends on the task. Also note that it doesn’t need to be same across the ERS. For instance, if the error at the current time step is small enough, you may be able to skip to the next time step without iterating K times (kind of adaptive iteration).
Pros & Cons of ERS
Pros
- The model can adapt to changing environment by consistently updating its internal states.
- Also, the model can recognize intention behind the perceived observation.
- (I think) It’s a cool way of implementing PE minimization in the neural network models.
Cons
- Computation of the ERS can be demanding sometimes, if you use high-dimensional data at the output layer (e.g., pixel-level images)
- Additional hyper-parameters (size of the window, number of iteration) are required.
In the next posting, I’ll talk about what I found from performing the ERS on my model.
References
- J. Tani, Exploring Robotic Minds: Actions, Symbols, and Consciousness As Self-Organizing Dynamic Phenomena. New York, NY, USA: Oxford Univ. Press, 2016.
- J. Hwang, J. Kim, A. Ahmadi, M. Choi and J. Tani, “Dealing With Large-Scale Spatio-Temporal Patterns in Imitative Interaction Between a Robot and a Human by Using the Predictive Coding Framework,” in IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. PP, no. 99, pp. 1-14.
