
A Little Thought on Open-Loop and Closed-Loop Generation
In our study, we often mention ‘open-loop’ and ‘closed-loop’ generation. Although this is very popular in control theory, it is relatively rare in our field - cognitive neurorobotics. Here in this posting, I’ll briefly introduce what it is and how we use it.
In our study, open-loop and closed-loop generation can be differentiated in terms of the input to the network. In the examples below, I’ll assume that we train the model to generate a 1-step look-ahead prediction.
Open-Loop
In the open-loop method, the sensory input is directly fed from an external source. For instance, in the open-loop ‘training’ process, the input to the model $x_t$ is obtained from the dataset $x^*$. Similarly, in the open-loop ‘testing’ process (with a real robot, for example), the image obtained from the camera is used as an input to the network.

Closed-Loop
In the closed-loop method, the input to the network $x_t$ is the output of the model (usually in the previous time step, such as $y_{t-1}$). This means that the model can generate the output without external observation (i.e. mental simulation).
The thing is that it doesn’t need to be either open-loop and closed-loop. We can set something called ‘closed-loop ratio $\gamma$ ‘ and control the input to the model like this:
$x_t=\gamma y_{t-1} + (1-\gamma)x^*_t$So it’s possible to have something like ‘half-open half-closed-loop’ training by setting $\gamma$ as 0.5.
So.. which method should I use when I train the model?
Well, I think there’s no concrete answer to this question since it may differ depending on the task, experiment and many other factors. Instead, I’d like to show one simple example from my work [1].
In brief, the goal of the study was to understand how the neural network can generate some new (and creative) actions from learning basic actions. I trained the neural network model to learn 6 actions. During the training process, I had 3 different “Closed-loop” ratios and compared the performance of those 3 different conditions.
What I found was that the closed-loop ratio had a huge impact on generating novel actions. Particularly, the structure of the “action encoding (AE) module” differed a lot depending on the closed-loop ratio. (You can consider the AE module as a sort of memory structure developed during training.)
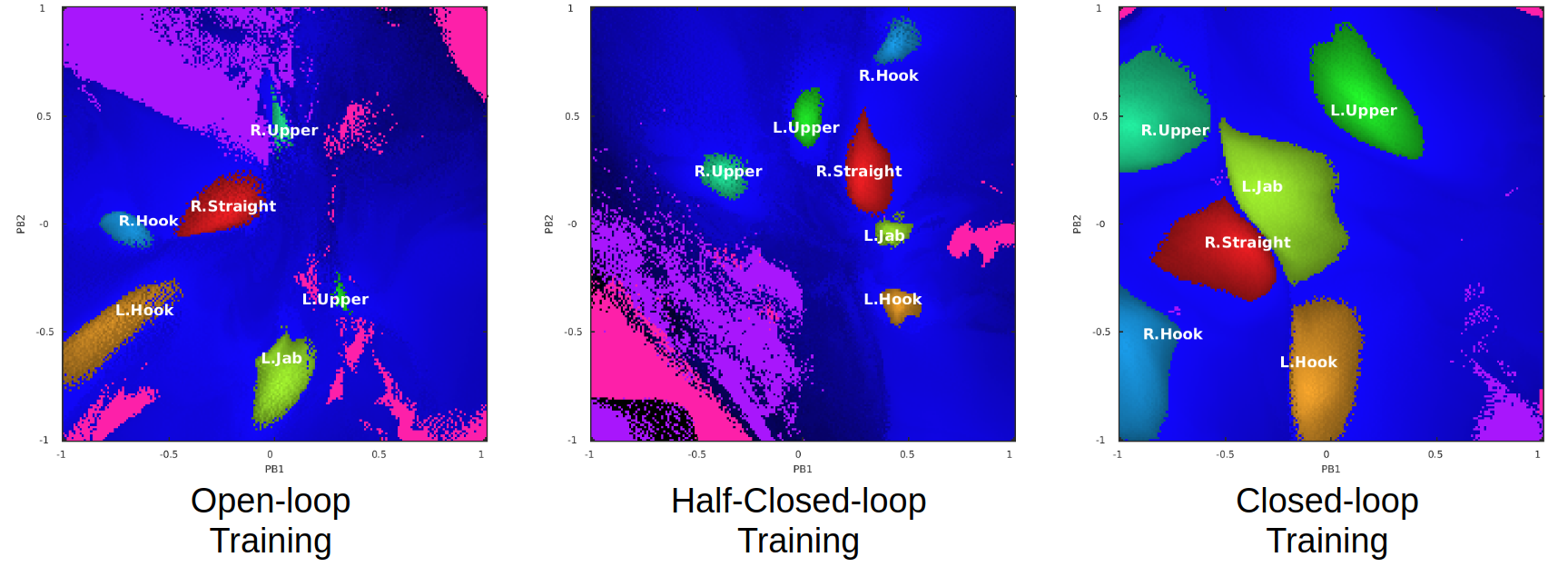 PB Space in 3 different conditions
PB Space in 3 different conditionsThese are the plots of the action encoding module developed in 3 different conditions. X and Y axis denotes the value of the neuron (Parametric Biases) and the colors represent the type of the actions. Each (x, y) position in the action encoding module is encoding 1 action. Then, we color-coded the AE module to illustrate which actions are encoded in which regions.
When the network was trained in the open-loop manner, the model generated fewer ‘stable’ patterns (i.e. many of them were too noisy so they couldn’t be used to generate action). When the model was trained in the closed-loop manner, the model generated ‘too’ stable patterns, showing fewer novel actions. When the model was trained in a half-closed-half-open loop, it generated many novel actions, indicating the highest level of creativity (well, in my measure).
So what I assume here is that during the closed-loop training, it was probably very hard to learn the primitive actions. Therefore, the model developed the action encoding module in which a larger portion of the area was devoted to generating the primitive actions. In contrast, the learning in the open-loop condition was easier since the “clean” input was always given from the dataset. Well, this only illustrates one possible impact of the open/closed-loop training on developing internal structure. It’d be interesting if I can do a bit more study about it.
Open and Close-loop in Perceptual Process
One interpretation about open/closed-loop methods is that it illustrates the different way of perceiving the environment. Let’s assume that the neural network model (embedded in the robot) is perceiving visual inputs (from the camera).
In the open-loop condition, the visual scene obtained from the camera will be directly fed to the network as input. Then, based on those inputs, the neural activation will be computed - i.e. sensory input is entraining the neural dynamics (i.e. sensory entrainment).
In the closed-loop condition, it works differently. The visual scene from the camera is not fed to the input of the model. Consequently, the current observation does not have any influences on neural activation. Therefore, we need additional mechanism which can make the model to be influenced by observation. In our study, we use an error minimization mechanism called error regression scheme (ERS). During the ERS, the observation (e.g. one from the camera) is not used as an input. Instead, Then, the model compares its prediction with the external sensory observation. There’d be a mismatch between them and this mismatch is often called ‘prediction error‘. Then, this prediction error (PE) is backpropagated from the lower-level to the higher-level and the neuron’s activation is optimized in the direction of minimizing prediction error.
So.. which one is more (biologically) plausible? Do we always minimize prediction error? or do we ignore them sometimes? Can we integrate both of them in one framework? Which one will perform better in practical application? There are many interesting questions (and some might be answered already!).
Reference
[1] Hwang, J., & Tani, J. (2018). A Dynamic Neural Network Approach to Generating Robot’s Novel Actions: A Simulation Experiment. Accepted in the 15th International Conference on Ubiquitous Robots (UR2018). [arXiv]
